|

|
Research |

|
Google Research ICML, 2024 blog / arXiv / bibtex A general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. |
|
|
Jiarui Xu, Xingyi Zhou, Shen Yan, Xiuye Gu, Anurag Arnab, Chen Sun, Xiaolong Wang, Cordelia Schmid CVPR, 2024 arXiv / code / bibtex We propose PixelLLM to equip LLMs with pixel-aligned localization capability. |

|
Xingyi Zhou, Anurag Arnab, Shyamal Buch, Shen Yan, Austin Myers, Xuehan Xiong, Arsha Nagrani, Cordelia Schmid CVPR, 2024 arXiv / code / bibtex An online video captioner based on token clustering and streaming decoding. |
|
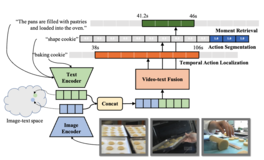
Shen Yan*, Xuehan Xiong*, Arsha Nagrani, Anurag Arnab, Zhonghao Wang, Weina Ge, David Ross, Cordelia Schmid ICCV, 2023 arXiv / code / bibtex UnLoc unifies moment retrieval, temporal localization and action segmentation with a single stage model. |
|
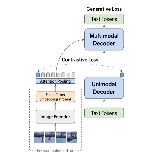
Shen Yan*, Tao Zhu*, Zirui Wang, Yuan Cao, Mi Zhang, Soham Ghosh, Yonghui Wu, Jiahui Yu arXiv, 2023 arXiv / bibtex VideoCoCa maximally reuses pretrained CoCa and minimizes additional training cost. |
|
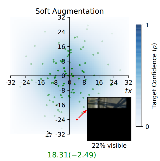
Yang Liu, Shen Yan, Laura Leal-Taixé, James Hays, Deva Ramanan CVPR, 2023 arXiv / code / bibtex Soft augmentations produce better calibrated models on occluded examples. |
|
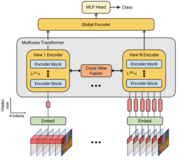
Shen Yan, Xuehan Xiong, Anurag Arnab, Zhichao Lu, Mi Zhang, Chen Sun, Cordelia Schmid CVPR, 2022 arXiv / code / bibtex A simple method for capturing multiresolution temporal context in transformers. |
|
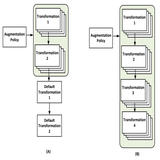
Yu Zheng, Zhi Zhang, Shen Yan, Mi Zhang ICLR, 2022 arXiv / code / bibtex / slides Build a data augmentation policy progressively based on regularized gradient matching. |
|
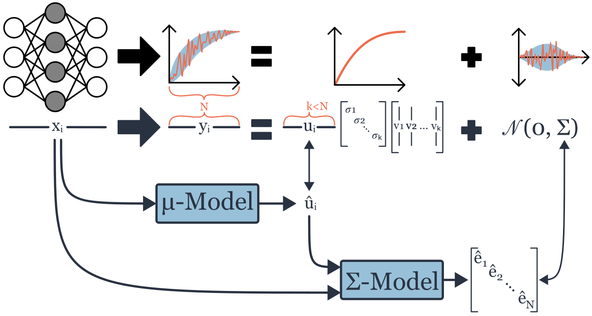
Shen Yan*, Colin White*, Yash Savani, Frank Hutter NeurIPS, 2021 arXiv / code / bibtex / slides A surrogate method to create multi-fidelity NAS benchmarks. |
|
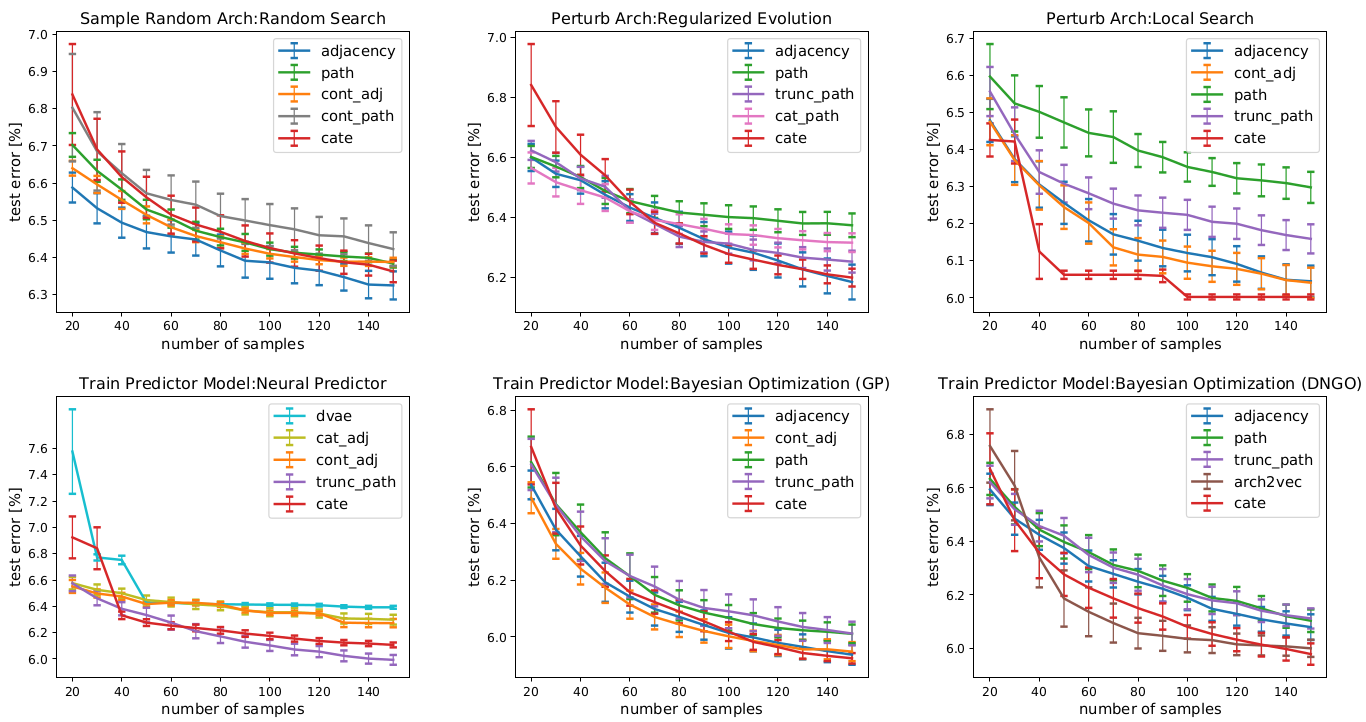
Shen Yan, Kaiqiang Song, Fei Liu, Mi Zhang ICML, 2021 (Long Presentation) video: 17 min/ arXiv / code / bibtex Pre-training computation-aware architecture embeddings can also help with architecture search. |
 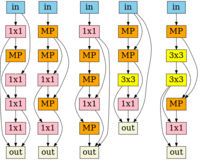
|
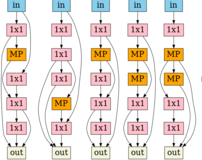
Shen Yan, Yu Zheng, Wei Ao, Xiao Zeng, Mi Zhang NeurIPS, 2020 video: 3 min/ arXiv / code / bibtex Pre-training structure-aware architecture embeddings help architecture search. |
 
|
Taojiannan Yang, Sijie Zhu, Chen Chen, Shen Yan, Mi Zhang, Andrew Wills ECCV, 2020 (Oral) video: 10 min/ arXiv / code / bibtex Mutual learning with input resolution and network width improves accuracy-efficiency tradeoffs. |
|
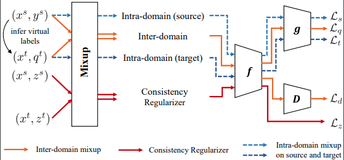
Shen Yan, Huan Song, Nanxiang Li, Lincan Zou, Liu Ren arXiv, 2020 arXiv / code / bibtex Mixup can help with unsupervised domain adaptation. |
|
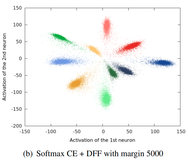
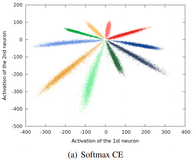
Harald Hanselmann, Shen Yan, Hermann Ney BMVC, 2017 bibtex We extend the center loss with an inter-class loss reminiscent of the popular early face recognition approach Fisherfaces. |
Service |
|
|